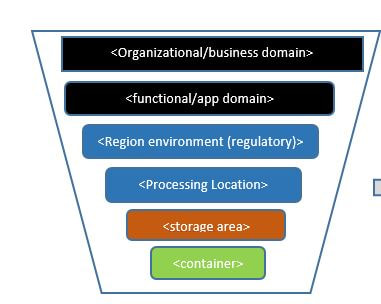
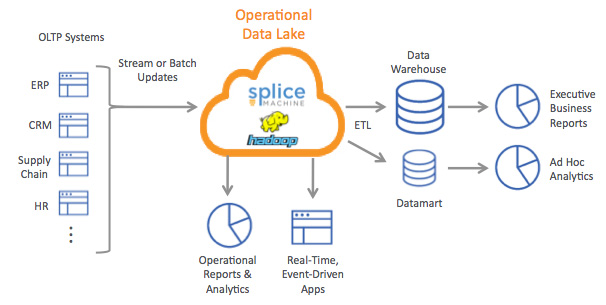
For best data insight and data visibility it is important to seperate source data based on following factors:
- Types of data :Information about types of data , frequency (Batch, real-time or near real-time mode)
- Usage : What the data can be used for
- End User :Who would be using and purpose
- Long Term and Short Term usage :How long the data need to be used for
- Maximum usability : Is there a limit of the data
- Expiry date : Is there a time line where the data expiry
- Base on the above points separate the data.
For the frequently use data keep in the faster access storage or db
Less frequently access or unused data store the different storage place
Take a current snap shot of the data or back up before purge the data from the fast access DB.





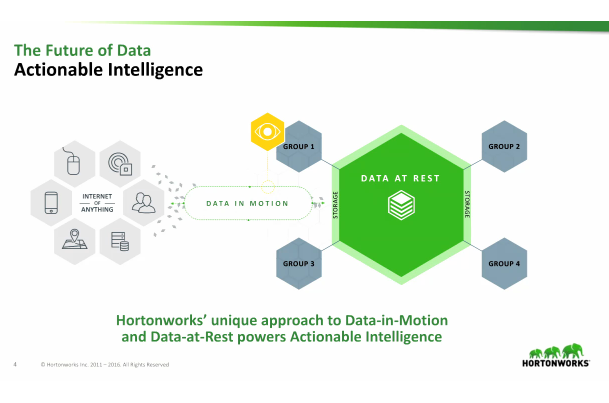
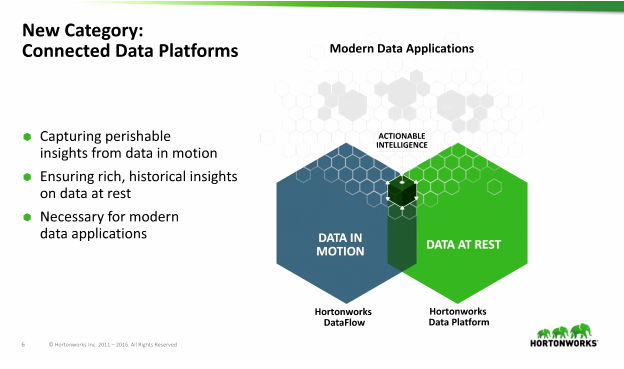
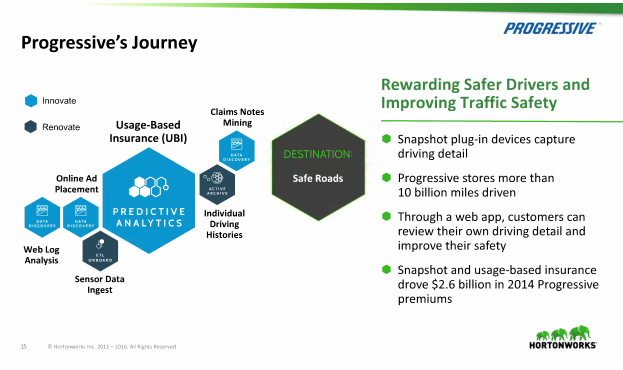
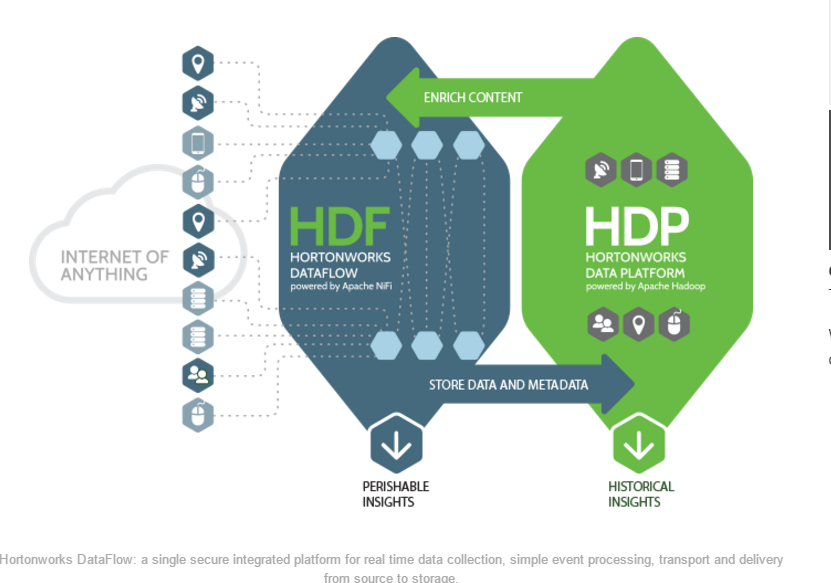
 RSS Feed
RSS Feed
