
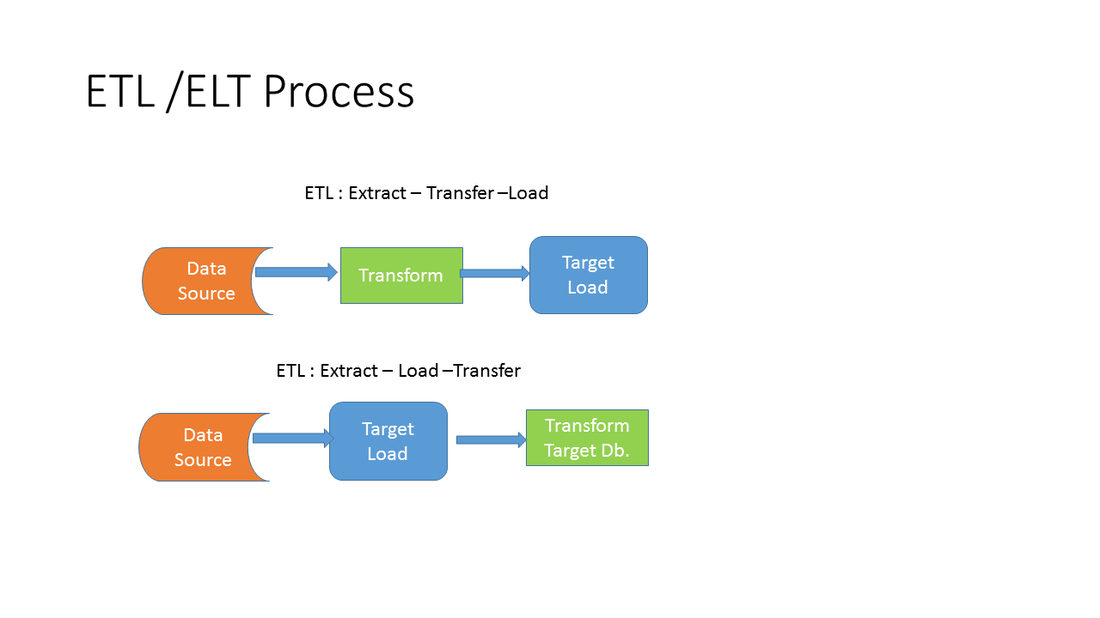
etl : extract transfer load |
AUTHORAjit Dash 24+ Years’ experience in Data Analytics, Data Sc, Data Bases, Data warehouse,Business Analytics, Business Intelligence, Bigdata and Data Sc. etc..
Archives
December 2023
Categories |


 RSS Feed
RSS Feed

{kind=link}