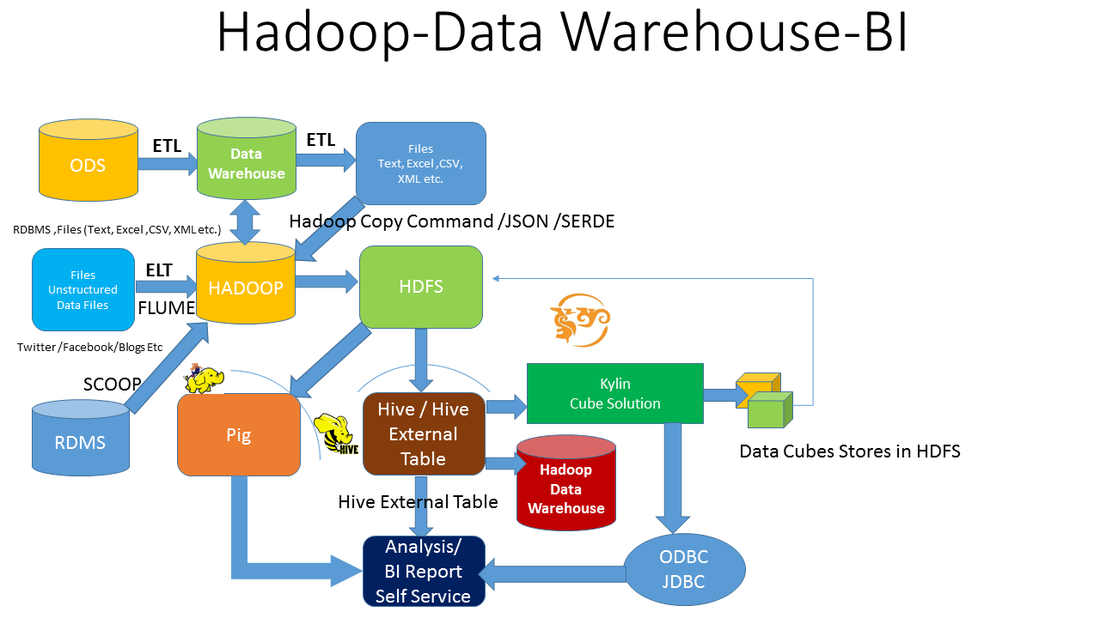
ETL : Extract Transfer Load
ELT: Extract Transfer Load
ELT: Extract Transfer Load

SPARK ACCESS
spark = SparkSession.builder \
... .master("local") \
... .appName("Word Count") \
... .config("spark.some.config.option", "some-value") \
# Verify SparkContext
print (sc)
# Print Spark version
print(sc.version)
From pyspark.sql import SparkSession
# Create my_spark
my_spark = SparkSession.builder.getOrCreate()
# Print my_spark
print(my_spark)
3.# view the tables in the catalog
print(spark.catalog.listTables())
4. # Don't change this query
query = "FROM flights SELECT * LIMIT 10"
(Also us can use # query1 = " SELECT * from flights LIMIT 2")
# Get the first 10 rows of flights
flights10 = spark.sql(query)
5## Convert to Panda .toPandas()
query = "SELECT origin, dest, COUNT(*) as N FROM flights GROUP BY origin, dest"
# Run the query
flight_counts = spark.sql(query)
print(flight_counts.show())
# Convert the results to a pandas DataFrame
pd_counts = flight_counts.toPandas()
6.Data Frame
# Create spark_temp from pd_temp
spark_temp = spark.createDataFrame(pd_temp)
# Examine the tables in the catalog
print(spark.catalog.listTables())
# Add spark_temp to the catalog
spark_temp.createOrReplaceTempView("temp")
7. df = spark.read \
.format("csv") \
.option("header","true") \
.option("inferSchema","true") \
.option("nullValue","NA") \
.option("timestampFormat","yyyy-MM-dd'T'HH:mm:ss") \
.option("mode","failfast") \
.option("path","/home/prashant/spark-data/survey.csv") \
.load()
Also a file_ path = df = sparkSess.read
.csv("C:\\vikas\\spark\\Interview\\text.txt")
Df=spark.rad.csv(filepath,header =true ,interSchema =true)
Create table with data
data=\
[("url1", "2018-08-15 00:00:00","tw", 1),
("url1", "2018-08-15 00:05:00","tw",3),
("url1", "2018-08-15 00:11:00","tw", 1)]
dfnew = sqlContext.createDataFrame(data, ["url", "ts","service", "delta"])
dfnew.registerTempTable("newdata") # create temporary table
Add a new column
8. # Create the DataFrame flights
#creating from table
flights = spark.table("flights")
# Show the head
print(flights.show())
# Add duration_hrs
flights = flights.withColumn("duration_hrs",flights.hour+1)
print(flights.show())
9. # Select the first set of columns
selected1 = flights.select("taIlnum","origin","dest")
# Select the second set of columns
temp = flights.select(flights.origin,flights.dest, flights.carrier)
# Define first filter
filterA = flights.origin == "SEA"
# Define second filter
filterB = flights.origin == "PDX"
# Filter the data, first by filterA then by filterB
selected2 = temp.filter(filterA).filter(filterB)
print (selected2.show())
print (selected1.show())
print (temp.show())
selected3 = temp.filter(filterA).show()
selected4 = temp.filter(filterB).show()
selected5 = temp.filter(filterA).filter(filterB).show()
10.
# Define avg_speed
avg_speed = (flights.distance/(flights.air_time/60)).alias("avg_speed")
# Select the correct columns
speed1 = flights.select("origin", "dest", "tailnum", avg_speed)
# Create the same table using a SQL expression
speed2 = flights.selectExpr("origin", "dest", "tailnum", "distance/(air_time/60) as avg_speed")
# Find the shortest flight from PDX in terms of distance
flights.filter(flights.origin == "PDX").groupBy().min("distance").show()
# Find the longest flight from SEA in terms of air time
flights.filter(flights.origin == "SEA").groupBy().max("air_time").show()
12. # Group by tailnum
by_plane = flights.groupBy("tailnum").count().show()
# Number of flights each plane made
#by_plane.count().show()
# Group by origin
by_origin = flights.groupBy("origin").avg("air_time").show()
# Average duration of flights from PDX and SEA
#by_origin.avg("air_time").show()
14.
# Import pyspark.sql.functions as F
import pyspark.sql.functions as F
# Group by month and dest
by_month_dest = flights.groupBy("month","dest")
# Average departure delay by month and destination
by_month_dest.avg("dep_delay").show()
# Standard deviation of departure delay
by_month_dest.agg(F.stddev("dep_delay")).show()
collect() show all the records
show() show only top 20 records
take() show the value entered take(2) only 2
Join :
# Examine the data
print(airports.show())
# Rename the faa column
airports = airports.withColumnRenamed("faa","dest")
print(airports.show())
# Join the DataFrames
flights_with_airports =flights. Join(airports,'dest' , 'leftouter')
# Examine the new DataFrame
print(flights_with_airports.show())
RDD SPLIT
https://hackersandslackers.com/working-with-pyspark-rdds/ : GOOD
#/usr/local/share/datasets/airports.csv
#Create a RDD AS MYRDD
myrdd =sc.textFile("/usr/local/share/datasets/airports.csv")
#rdd.collect()
# SHOW THE COLLECTIONS
myrdd.collect()
#Take out the header
headers = myrdd.first()
myrdd1 = myrdd.filter(lambda line: line != headers)
#print the first element it shows no header
myrdd1.take(1)
Out[55]: ['"04G","Lansdowne Airport",41.1304722,-80.6195833,1044,-5,"A"']
With split command
#animalRDD = animalRDD.map(lambda line: line.split(","))
myrdd1 =myrdd1.map(lambda line: line.split(","))
myrdd1.take(3)
Rdd = sc.textFile('/FileStore/tables/animals.txt').take(5)
Multiple text file ike S3 bucketrdd = rdd.wholeTextFiles("/path/to/my/directory")
delimiter:animalRDD = animalRDD.map(lambda line: line.split(","))
No: RDD TO Data Frame : toDF
headers = full_csv.first() rdd = rdd.filter(lambda line: line != headers)
spark's substr function can handle fixed-width columns, for example:
df = spark.read.text("/tmp/sample.txt")
df.select(
df.value.substr(1,3).alias('id'),
df.value.substr(4,8).alias('date'),
df.value.substr(12,3).alias('string'),
df.value.substr(15,4).cast('integer').alias('integer')
).show()
will result in:
+---+--------+------+-------+
| id| date|string|integer|
+---+--------+------+-------+
|001|01292017| you| 1234|
|002|01302017| me| 5678|
+---+--------+------+-------+
WORD COUNT & SPLIT:
https://pythonexamples.org/pyspark-word-count-example/ --good
https://www.tutorialkart.com/apache-spark/python-spark-shell-pyspark-example/ : exaplins
import sys
from pyspark import SparkContext, SparkConf
if __name__ == "__main__":
# create Spark context with necessary configuration
sc = SparkContext("local","PySpark Word Count Exmaple")
# read data from text file and split each line into words
words = sc.textFile("D:/workspace/spark/input.txt").flatMap(lambda line: line.split(" "))
# count the occurrence of each word
wordCounts = words.map(lambda word: (word, 1)).reduceByKey(lambda a,b:a +b)
# save the counts to output
wordCounts.saveAsTextFile("D:/workspace/spark/output/")
Word count
import pyspark.sql.functions as f
df = df.withColumn('wordCount', f.size(f.split(f.col('Description'), ' '))).show()
#df = df.withColumn('wordCount1', f.size(f.split(f.col('Description'),' '))).show()
df = spark.sql("select count(*) from df " ).show()
Window function
https://mode.com/blog/bridge-the-gap-window-functions
https://medium.com/jbennetcodes/how-to-get-rid-of-loops-and-use-window-functions-in-pandas-or-spark-sql-907f274850e4 : good
https://databricks.com/blog/2015/07/15/introducing-window-functions-in-spark-sql.html
data=\
[("Thin", "Cell Phone", 6000),
("Normal", "Tablet", 1500),
("Mini", "Tablet", 5500),
("Ultra thin", "Cell Phone", 5500),
("Very thin", "Cell Phone", 6000),
("Big", "Tablet", 2500),
("Bendable", "Cell Phone", 3000),
("Foldable", "Cell Phone", 3000),
("Pro", "Tablet", 4500),
("Pro2", "Tablet", 6500)]
df = sqlContext.createDataFrame(data, ["product", "category", "revenue"])
df.registerTempTable("productRevenue")
# example2
from pyspark.sql.window import Window
import pyspark.sql.functions as func
from pyspark.sql.functions import lit
data=\
[("url1", "2018-08-15 00:00:00","tw", 1),
("url1", "2018-08-15 00:05:00","tw",3),
("url1", "2018-08-15 00:11:00","tw", 1)]
dfnew = sqlContext.createDataFrame(data, ["url", "ts","service", "delta"])
dfnew.registerTempTable("newdata")
#dfnew.show()
#show newdata tabel
dff = spark.sql("select * from newdata")
dff.show()
#Calculate total value of each row by suming with privious row
df2= sqlContext.sql("select *,sum(delta) over (partition by url, service order by ts) as total from newdata")
df2.show()
#store in a temprary view
df2.createOrReplaceTempView('df2')
df2.show()
#also store in a temprary table
df2.registerTempTable("withtotal")
df2.show()
##Calculate delta value of each row from total with lag window functions
df3 = sqlContext.sql("select *,lag(total, 1, 0)over (partition by url,service order by ts) as prev from withtotal ") # or from df2
#df3=df2.select("total").show() --showing one column
df3.show()
df3 = df3.withColumn('delta calculate', df3['total'] - df3['prev'])
df3.show()
#rank calculE
data=\
[("url10", "tw",250),
("url11", "fb",400),
("url11", "tw",310),
("url11", "ff",400),
("url11", "fb",10000),
("url11", "ff",200),
("url11", "tw",700),]
df4 = sqlContext.createDataFrame(data, ["url", "service","total"])
df4.registerTempTable("ranktable")
df4.createOrReplaceTempView('df4')
df4.show()
df4 =sqlContext.sql ("select *,rank() over(partition by url order by total desc ) as rnk from ranktable")
df4.show()
#RANK , DESNSE RANK ETC
df6= sqlContext.createDataFrame([('a', 10), ('a', 10), ('a', 20)],
['x', 'y'])
df6.show()
df6.createOrReplaceTempView('df6')
df6.show()
df6 =sqlContext.sql("select * ,rank()over(partition by x order by y) as rnk,row_number() over (partition by x order by y) as row_numbe,dense_rank() over (partition by x order by y) as dnsrnk from df6").show()
select * ,percent_rank() over(partition by x order by y) as perrank,select * ,dense_rank() over(partition by x order by y) as denesrank from df6")
df6.show()
wordcount :
https://adataanalyst.com/spark/building-word-count-application-spark/ -- good
https://stackoverflow.com/questions/35258586/pyspark-perform-word-count-in-an-rdd-comprised-of-arrays-of-strings
from pyspark import SparkContext
from operator import add
sc = SparkContext(appName="Words")
lines = sc.textFile(sys.argv[1], 1) # this is an RDD
# counts is an rdd is of the form (word, count)
counts = lines.flatMap(lambda x: [(w.lower(), 1) for w in x.split()]).reduceByKey(add)
# collect brings it to a list in local memory
output = counts.collect()
for (word, count) in output:
print "%s: %i" % (word, count)
sc.stop() # stop the spark context
https://stackoverflow.com/questions/48927271/count-number-of-words-in-a-spark-dataframe
Countwords:
https://stackoverflow.com/questions/48927271/count-number-of-words-in-a-spark-dataframe
· Use pyspark.sql.functions.split() to break the string into a list
· Use pyspark.sql.functions.size() to count the length of the list
https://pythonexamples.org/pyspark-word-count-example/ --good
https://www.tutorialkart.com/apache-spark/python-spark-shell-pyspark-example/ : exaplins
https://s3.amazonaws.com/assets.datacamp.com/blog_assets/PySpark_SQL_Cheat_Sheet_Python.pdfhttps://s3.amazonaws.com/assets.datacamp.com/blog_assets/Numpy_Python_Cheat_Sheet.pdf
http://datacamp-community-prod.s3.amazonaws.com/dbed353d-2757-4617-8206-8767ab379ab3
https://storage.googleapis.com/molten/lava/2018/09/81bb9282-intro-to-python-for-data-science-python-cheat-sheet-datacamp.jpg
https://s3.amazonaws.com/assets.datacamp.com/blog_assets/PySpark_Cheat_Sheet_Python.pdf
... .master("local") \
... .appName("Word Count") \
... .config("spark.some.config.option", "some-value") \
# Verify SparkContext
print (sc)
# Print Spark version
print(sc.version)
- Session: Create or check a new session
From pyspark.sql import SparkSession
# Create my_spark
my_spark = SparkSession.builder.getOrCreate()
# Print my_spark
print(my_spark)
3.# view the tables in the catalog
print(spark.catalog.listTables())
4. # Don't change this query
query = "FROM flights SELECT * LIMIT 10"
(Also us can use # query1 = " SELECT * from flights LIMIT 2")
# Get the first 10 rows of flights
flights10 = spark.sql(query)
5## Convert to Panda .toPandas()
query = "SELECT origin, dest, COUNT(*) as N FROM flights GROUP BY origin, dest"
# Run the query
flight_counts = spark.sql(query)
print(flight_counts.show())
# Convert the results to a pandas DataFrame
pd_counts = flight_counts.toPandas()
6.Data Frame
# Create spark_temp from pd_temp
spark_temp = spark.createDataFrame(pd_temp)
# Examine the tables in the catalog
print(spark.catalog.listTables())
# Add spark_temp to the catalog
spark_temp.createOrReplaceTempView("temp")
7. df = spark.read \
.format("csv") \
.option("header","true") \
.option("inferSchema","true") \
.option("nullValue","NA") \
.option("timestampFormat","yyyy-MM-dd'T'HH:mm:ss") \
.option("mode","failfast") \
.option("path","/home/prashant/spark-data/survey.csv") \
.load()
Also a file_ path = df = sparkSess.read
.csv("C:\\vikas\\spark\\Interview\\text.txt")
Df=spark.rad.csv(filepath,header =true ,interSchema =true)
Create table with data
data=\
[("url1", "2018-08-15 00:00:00","tw", 1),
("url1", "2018-08-15 00:05:00","tw",3),
("url1", "2018-08-15 00:11:00","tw", 1)]
dfnew = sqlContext.createDataFrame(data, ["url", "ts","service", "delta"])
dfnew.registerTempTable("newdata") # create temporary table
Add a new column
8. # Create the DataFrame flights
#creating from table
flights = spark.table("flights")
# Show the head
print(flights.show())
# Add duration_hrs
flights = flights.withColumn("duration_hrs",flights.hour+1)
print(flights.show())
9. # Select the first set of columns
selected1 = flights.select("taIlnum","origin","dest")
# Select the second set of columns
temp = flights.select(flights.origin,flights.dest, flights.carrier)
# Define first filter
filterA = flights.origin == "SEA"
# Define second filter
filterB = flights.origin == "PDX"
# Filter the data, first by filterA then by filterB
selected2 = temp.filter(filterA).filter(filterB)
print (selected2.show())
print (selected1.show())
print (temp.show())
selected3 = temp.filter(filterA).show()
selected4 = temp.filter(filterB).show()
selected5 = temp.filter(filterA).filter(filterB).show()
10.
# Define avg_speed
avg_speed = (flights.distance/(flights.air_time/60)).alias("avg_speed")
# Select the correct columns
speed1 = flights.select("origin", "dest", "tailnum", avg_speed)
# Create the same table using a SQL expression
speed2 = flights.selectExpr("origin", "dest", "tailnum", "distance/(air_time/60) as avg_speed")
# Find the shortest flight from PDX in terms of distance
flights.filter(flights.origin == "PDX").groupBy().min("distance").show()
# Find the longest flight from SEA in terms of air time
flights.filter(flights.origin == "SEA").groupBy().max("air_time").show()
12. # Group by tailnum
by_plane = flights.groupBy("tailnum").count().show()
# Number of flights each plane made
#by_plane.count().show()
# Group by origin
by_origin = flights.groupBy("origin").avg("air_time").show()
# Average duration of flights from PDX and SEA
#by_origin.avg("air_time").show()
14.
# Import pyspark.sql.functions as F
import pyspark.sql.functions as F
# Group by month and dest
by_month_dest = flights.groupBy("month","dest")
# Average departure delay by month and destination
by_month_dest.avg("dep_delay").show()
# Standard deviation of departure delay
by_month_dest.agg(F.stddev("dep_delay")).show()
collect() show all the records
show() show only top 20 records
take() show the value entered take(2) only 2
Join :
# Examine the data
print(airports.show())
# Rename the faa column
airports = airports.withColumnRenamed("faa","dest")
print(airports.show())
# Join the DataFrames
flights_with_airports =flights. Join(airports,'dest' , 'leftouter')
# Examine the new DataFrame
print(flights_with_airports.show())
RDD SPLIT
https://hackersandslackers.com/working-with-pyspark-rdds/ : GOOD
#/usr/local/share/datasets/airports.csv
#Create a RDD AS MYRDD
myrdd =sc.textFile("/usr/local/share/datasets/airports.csv")
#rdd.collect()
# SHOW THE COLLECTIONS
myrdd.collect()
#Take out the header
headers = myrdd.first()
myrdd1 = myrdd.filter(lambda line: line != headers)
#print the first element it shows no header
myrdd1.take(1)
Out[55]: ['"04G","Lansdowne Airport",41.1304722,-80.6195833,1044,-5,"A"']
With split command
#animalRDD = animalRDD.map(lambda line: line.split(","))
myrdd1 =myrdd1.map(lambda line: line.split(","))
myrdd1.take(3)
Rdd = sc.textFile('/FileStore/tables/animals.txt').take(5)
Multiple text file ike S3 bucketrdd = rdd.wholeTextFiles("/path/to/my/directory")
delimiter:animalRDD = animalRDD.map(lambda line: line.split(","))
No: RDD TO Data Frame : toDF
headers = full_csv.first() rdd = rdd.filter(lambda line: line != headers)
spark's substr function can handle fixed-width columns, for example:
df = spark.read.text("/tmp/sample.txt")
df.select(
df.value.substr(1,3).alias('id'),
df.value.substr(4,8).alias('date'),
df.value.substr(12,3).alias('string'),
df.value.substr(15,4).cast('integer').alias('integer')
).show()
will result in:
+---+--------+------+-------+
| id| date|string|integer|
+---+--------+------+-------+
|001|01292017| you| 1234|
|002|01302017| me| 5678|
+---+--------+------+-------+
WORD COUNT & SPLIT:
https://pythonexamples.org/pyspark-word-count-example/ --good
https://www.tutorialkart.com/apache-spark/python-spark-shell-pyspark-example/ : exaplins
import sys
from pyspark import SparkContext, SparkConf
if __name__ == "__main__":
# create Spark context with necessary configuration
sc = SparkContext("local","PySpark Word Count Exmaple")
# read data from text file and split each line into words
words = sc.textFile("D:/workspace/spark/input.txt").flatMap(lambda line: line.split(" "))
# count the occurrence of each word
wordCounts = words.map(lambda word: (word, 1)).reduceByKey(lambda a,b:a +b)
# save the counts to output
wordCounts.saveAsTextFile("D:/workspace/spark/output/")
Word count
import pyspark.sql.functions as f
df = df.withColumn('wordCount', f.size(f.split(f.col('Description'), ' '))).show()
#df = df.withColumn('wordCount1', f.size(f.split(f.col('Description'),' '))).show()
df = spark.sql("select count(*) from df " ).show()
Window function
https://mode.com/blog/bridge-the-gap-window-functions
https://medium.com/jbennetcodes/how-to-get-rid-of-loops-and-use-window-functions-in-pandas-or-spark-sql-907f274850e4 : good
https://databricks.com/blog/2015/07/15/introducing-window-functions-in-spark-sql.html
data=\
[("Thin", "Cell Phone", 6000),
("Normal", "Tablet", 1500),
("Mini", "Tablet", 5500),
("Ultra thin", "Cell Phone", 5500),
("Very thin", "Cell Phone", 6000),
("Big", "Tablet", 2500),
("Bendable", "Cell Phone", 3000),
("Foldable", "Cell Phone", 3000),
("Pro", "Tablet", 4500),
("Pro2", "Tablet", 6500)]
df = sqlContext.createDataFrame(data, ["product", "category", "revenue"])
df.registerTempTable("productRevenue")
# example2
from pyspark.sql.window import Window
import pyspark.sql.functions as func
from pyspark.sql.functions import lit
data=\
[("url1", "2018-08-15 00:00:00","tw", 1),
("url1", "2018-08-15 00:05:00","tw",3),
("url1", "2018-08-15 00:11:00","tw", 1)]
dfnew = sqlContext.createDataFrame(data, ["url", "ts","service", "delta"])
dfnew.registerTempTable("newdata")
#dfnew.show()
#show newdata tabel
dff = spark.sql("select * from newdata")
dff.show()
#Calculate total value of each row by suming with privious row
df2= sqlContext.sql("select *,sum(delta) over (partition by url, service order by ts) as total from newdata")
df2.show()
#store in a temprary view
df2.createOrReplaceTempView('df2')
df2.show()
#also store in a temprary table
df2.registerTempTable("withtotal")
df2.show()
##Calculate delta value of each row from total with lag window functions
df3 = sqlContext.sql("select *,lag(total, 1, 0)over (partition by url,service order by ts) as prev from withtotal ") # or from df2
#df3=df2.select("total").show() --showing one column
df3.show()
df3 = df3.withColumn('delta calculate', df3['total'] - df3['prev'])
df3.show()
#rank calculE
data=\
[("url10", "tw",250),
("url11", "fb",400),
("url11", "tw",310),
("url11", "ff",400),
("url11", "fb",10000),
("url11", "ff",200),
("url11", "tw",700),]
df4 = sqlContext.createDataFrame(data, ["url", "service","total"])
df4.registerTempTable("ranktable")
df4.createOrReplaceTempView('df4')
df4.show()
df4 =sqlContext.sql ("select *,rank() over(partition by url order by total desc ) as rnk from ranktable")
df4.show()
#RANK , DESNSE RANK ETC
df6= sqlContext.createDataFrame([('a', 10), ('a', 10), ('a', 20)],
['x', 'y'])
df6.show()
df6.createOrReplaceTempView('df6')
df6.show()
df6 =sqlContext.sql("select * ,rank()over(partition by x order by y) as rnk,row_number() over (partition by x order by y) as row_numbe,dense_rank() over (partition by x order by y) as dnsrnk from df6").show()
select * ,percent_rank() over(partition by x order by y) as perrank,select * ,dense_rank() over(partition by x order by y) as denesrank from df6")
df6.show()
wordcount :
https://adataanalyst.com/spark/building-word-count-application-spark/ -- good
https://stackoverflow.com/questions/35258586/pyspark-perform-word-count-in-an-rdd-comprised-of-arrays-of-strings
from pyspark import SparkContext
from operator import add
sc = SparkContext(appName="Words")
lines = sc.textFile(sys.argv[1], 1) # this is an RDD
# counts is an rdd is of the form (word, count)
counts = lines.flatMap(lambda x: [(w.lower(), 1) for w in x.split()]).reduceByKey(add)
# collect brings it to a list in local memory
output = counts.collect()
for (word, count) in output:
print "%s: %i" % (word, count)
sc.stop() # stop the spark context
https://stackoverflow.com/questions/48927271/count-number-of-words-in-a-spark-dataframe
Countwords:
https://stackoverflow.com/questions/48927271/count-number-of-words-in-a-spark-dataframe
· Use pyspark.sql.functions.split() to break the string into a list
· Use pyspark.sql.functions.size() to count the length of the list
- import pyspark.sql.functions as f
https://pythonexamples.org/pyspark-word-count-example/ --good
https://www.tutorialkart.com/apache-spark/python-spark-shell-pyspark-example/ : exaplins
https://s3.amazonaws.com/assets.datacamp.com/blog_assets/PySpark_SQL_Cheat_Sheet_Python.pdfhttps://s3.amazonaws.com/assets.datacamp.com/blog_assets/Numpy_Python_Cheat_Sheet.pdf
http://datacamp-community-prod.s3.amazonaws.com/dbed353d-2757-4617-8206-8767ab379ab3
https://storage.googleapis.com/molten/lava/2018/09/81bb9282-intro-to-python-for-data-science-python-cheat-sheet-datacamp.jpg
https://s3.amazonaws.com/assets.datacamp.com/blog_assets/PySpark_Cheat_Sheet_Python.pdf
 RSS Feed
RSS Feed

{kind=link}