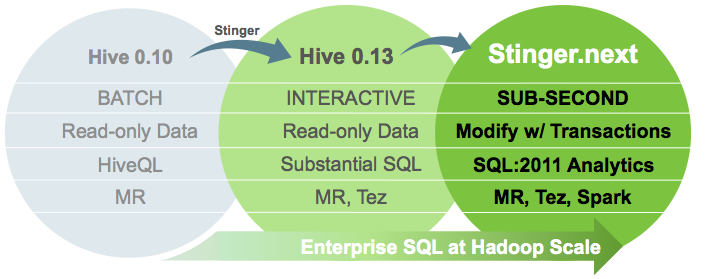
Stringer.next Ref: HN
|
Great Link : http://www.infoworld.com/article/2683729/hadoop/10-ways-to-query-hadoop-with-sql.html
Apache Phoenix is a relational database layer over HBase delivered as a client-embedded JDBC driver targeting low latency queries over HBase data. Apache Phoenix takes your SQL query, compiles it into a series of HBase scans, and orchestrates the running of those scans to produce regular JDBC result sets. The table metadata is stored in an HBase table and versioned, such that snapshot queries over prior versions will automatically use the correct schema. Direct use of the HBase API, along with coprocessors and custom filters, results in performance on the order of milliseconds for small queries, or seconds for tens of millions of rows.
Apache Phoenix: Its developers call it a "SQL skin for HBase" -- a way to query HBase with SQL-like commands via an embeddable JDBC driver built for high performance and read/write operations. Consider it an almost no-brainer for those making use of HBase, thanks to it being open source, aggressively developed, and outfitted with useful features like bulk data loading.
Hive has an optional component known as HiveServer or HiveThrift that allows access to Hive over a single port. Thrift is a software framework for scalable cross-language services development. See http://thrift.apache.org/ for more details. Thrift allows clients using languages including Java, C++, Ruby, and many others, to programmatically access Hive remotely.
Impala:
Impala is integrated from the ground up as part of the Hadoop ecosystem and leverages the same flexible file and data formats, metadata, security and resource management frameworks used by MapReduce, Apache Hive, Apache Pig and other components of the Hadoop stack. Designed to complement MapReduce which specializes in large-scale batch processing, Impala is an independent processing framework optimized for interactive queries. With Impala, analysts and data scientists now have the ability to perform real-time, “speed of thought” analytics on data stored in Hadoop via SQL or through Business Intelligence (BI) tools. The result is that large-scale data processing and interactive queries can be done on the same system using the same data and metadata – removing the need to migrate data sets into specialized systems and/or proprietary formats simply to perform analysis. Impala's SQL syntax follows the SQL-92 standard, and includes many industry extensions in areas such as built-in functions HiveQL Features not Available in Impala:
User-defined functions (UDFs) are supported starting in Impala 1.2. See User-Defined Functions (UDFs) for full details on Impala UDFs. HIVEQL NOT SUPPORTED BY HIVE Impala does not currently support these HiveQL statements:
Semantic Differences Between Impala and HiveQL Features Impala utilizes the Apache Sentry (incubating) authorization framework, which provides fine-grained role-based access control to protect data against unauthorized access or tampering The semantics of Impala SQL statements varies from HiveQL in some cases where they use similar SQL statement and clause names:
Apache Sentry (incubating) is a unified authorization mechanism so you can store sensitive data in Hadoop. Sentry provides Fine-grained authorization and role-based access control all through a single system
An enterprise data hub, powered by Hadoop, is a single, low-cost platform where organizations can efficiently and securely store, process, analyze, govern, archive, and serve any and all of their enterprise data. The enterprise hub provides access through the BI Tools , SQL etc. Main features are :
|
AUTHORAjit Dash 24+ Years’ experience in Data Analytics, Data Sc, Data Bases, Data warehouse,Business Analytics, Business Intelligence, Bigdata and Data Sc. etc..
Archives
December 2023
Categories |
 RSS Feed
RSS Feed
