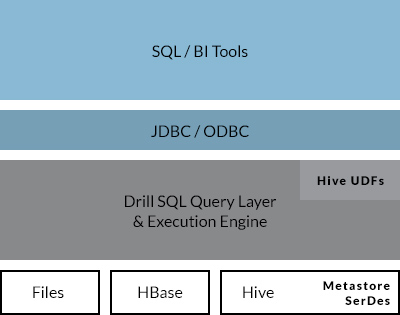
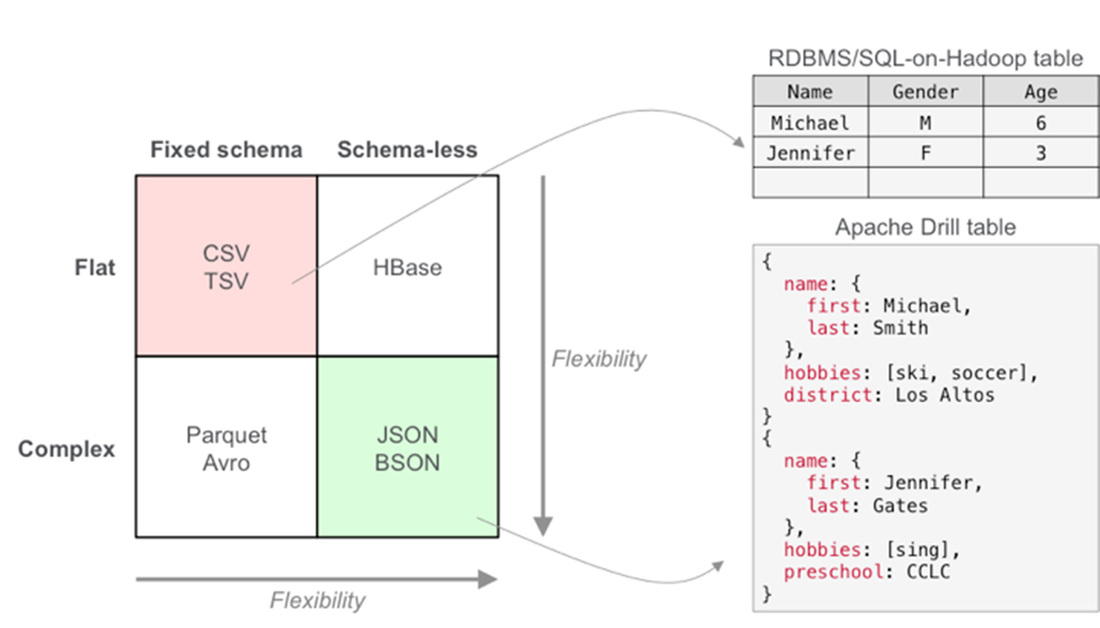
| | Drill uses the ANSI SQL and this minimizes the data preparation time like ETL etc. This also uses JSON like structure so Dynamic changes in the data model could be easily accepted It can interact with HIVE and HIVE UDF Modern big data applications such as social, mobile, web and IoT deal with a larger number of users and larger amount of data than the traditional transactional applications. The datasets associated with these applications evolve rapidly, are often self-describing and can include complex types such as JSON and Parquet. Apache Drill is built from the ground up to provide low latency queries natively on such rapidly evolving multi-structured datasets at scale. Apache Drill provides direct queries on self-describing and semi-structured data in files (such as JSON, Parquet) and HBase tables without needing to define and maintain schemas in a centralized store such as Hive metastore. This means that users can explore live data on their own as it arrives versus spending weeks or months on data preparation, modeling, ETL and subsequent schema management. Drill provides a JSON-like internal data model to represent and process data . |
|
0 Comments
Leave a Reply. |
AUTHORAjit Dash 24+ Years’ experience in Data Analytics, Data Sc, Data Bases, Data warehouse,Business Analytics, Business Intelligence, Bigdata and Data Sc. etc..
Archives
December 2023
Categories |
 RSS Feed
RSS Feed
